Achievement
Quantum Monte Carlo simulations reveal that Cooper pairs in the cuprate high-Tc superconductors are composed of electron holes on the Cu-d orbital and on the bonding molecular orbital constructed from the four surrounding O-p orbitals.
Significance and Impact
The results provide new information on the mechanism responsible for superconductivity in the cuprates and explain how an effective single-orbital Hubbard model successfully captures their properties.
Research Details
- Large-scale computations of a realistic three-band Hubbard model enabled, for the first time, a detailed study of the orbital structure of the cuprate pairing interaction
- The results provide strong support for the Zhang-Rice singlet framework, which constructs a quasiparticle that can effectively be described in terms of a simpler single-band model.
Overview
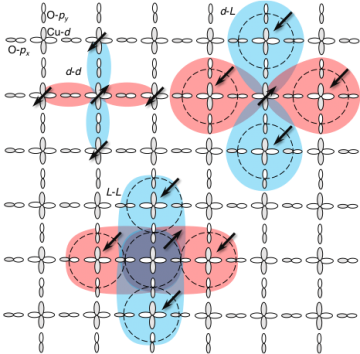
Quantum Monte Carlo simulations reveal that Cooper pairs in the cuprate high-temperature superconductors are composed of electron holes on the Cu-d and on the bonding molecular orbital L constructed from the four surrounding O-p orbitals. The results provide new information on the mechanism responsible for superconductivity in the cuprates and explain how an effective single-orbital Hubbard model successfully captures their properties.
A detailed study of the orbital structure of the cuprate pairing interaction was enabled, for the first time, by large-scale computations of a realistic three-band Hubbard model, which explicitly resolves the Cu-d and O-px/y orbitals of the CuO planes in these materials. The results show that the Cu-d and O bonding molecular orbital L components of the Cooper pairs have the same d-wave spatial structure with opposite signs along x- and y-directions. This provides strong support for the Zhang-Rice singlet framework, which constructs a quasiparticle from these components that
can effectively be described in terms of a simpler single-band model.
Last Updated: April 1, 2021 - 1:35 pm